![]() Je suis devenu un adepte du framework Play!. Je ne le pratique pas depuis longtemps, seulement depuis 10 mois environ. Mais la courbe d’apprentissage est vraiment rapide. Une semaine est suffisante pour être à l’aise et être autonome. J’ai la modeste prétention, dans cet article, de montrer 2 ou 3 trucs qui font de ce framework une nouvelle manière de voir le web en Java.
Je suis devenu un adepte du framework Play!. Je ne le pratique pas depuis longtemps, seulement depuis 10 mois environ. Mais la courbe d’apprentissage est vraiment rapide. Une semaine est suffisante pour être à l’aise et être autonome. J’ai la modeste prétention, dans cet article, de montrer 2 ou 3 trucs qui font de ce framework une nouvelle manière de voir le web en Java.
Pour commencer, Play! est très simple à installer. Il suffit de décompresser le zip dans un répertoire, et de créer une variable PLAY_HOME qui pointe sur ce répertoire. Play! a uniquement besoin de Java comme pré-requis pour fonctionner. Et c’est tout ! Pour rappel, la plupart des autres frameworks web Java ont au moins besoin d’un serveur d’application…
Comme Play! embarque un serveur web, il se suffit à lui-même. Cette notion est appelée “full-stack”. Elle signifie que Play! est autonome à la fois dans son mode de développement en proposant tout ce qu’il faut pour faire une application web, de la couche présentation à l’accès aux données, et également lors de l’exécution des applications Play! qui tournent grâce au serveur web intégré.
Play! propose de nombreuses fonctionnalités peu répandues dans le monde du web en java. Par exemple, le code modifié est pris à chaud par le serveur web, il suffit de rafraîchir le navigateur pour voir sa modification ! La gestion d’erreur est également poussée. Lorsqu’une exception se produit, l’erreur s’affiche très clairement dans le navigateur. Comme le montre l’image suivante :
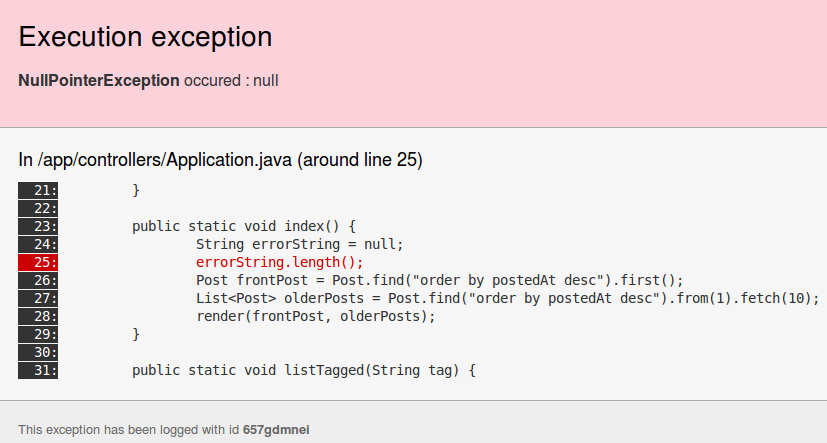
Le développement rapide est une des caractéristiques de Play! On passe beaucoup plus de temps à coder qu’à faire de la configuration ou de l’installation. Et ce n’est pas tout, Play! propose beaucoup de moyens d’accélérer le développement. Je vais donc vous en montrer quelques uns. Je ne compte pas énumérer tout ce qui fait que Play! permet de développer rapidement, mais seulement donner un aperçu.
Play! propose sur son site, une documentation très complète, ainsi qu’un tutoriel bien fait qui permet de se familiariser avec les notions principales du framework. Si on peut paraître sceptique devant tant de d’enthousiasme, faire le tutoriel permettra à quiconque de se rendre compte de la rapidité avec laquelle le développement se fait avec Play!.
Arborescence
Ceux qui connaissent Ruby on Rails et Grails ont déjà les bases pour Play!. Par exemple, l’arborescence des répertoires est très similaire :
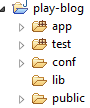
Les répertoires ont des noms explicites, par exemple le répertoire public permet au serveur web de renvoyer des ressources directement, telles que des images ou des scripts.
Le répertoire conf contient les fichiers de configuration comme son nom l’indique. Par défaut, Play! en crée trois :
- Un pour l’application de l’application et du serveur web
- Un pour définir les URL de l’application
- Un dernier contenant les messages de l’application
D’autres fichiers de configuration peuvent être créer dans ce répertoire, notamment pour chaque langue gérée par votre application.
La puissance dans le fichier de configuration
Application.conf est un fichier similaire à un fichier properties. Il est créé par Play! lors de la création d’une application. Il contient plein de valeurs essentielles pour configurer le serveur web, telles que le port à utiliser, le nom du cookie. Il contient également des propriétés permettant de configurer l’application comme la base de données, la configuration JPA, du cache…
Le gros avantage de ce fichier, est qu’il peut être l’unique fichier de configuration de l’application, et ce quel que soit l’environnement sur lequel est déployé la web app ! En effet Play! intègre un système qui permet de surcharger des valeurs dans le fichier de configuration. Lors du lancement de l’application, il suffit de préciser un paramètre supplémentaire sur la ligne de commande pour choisir les propriétés à appliquer. Comme ce n’est sûrement pas clair, voici un exemple :
%integration.application.mode=dev %production.application.mode=prod application.mode=dev
Le fichier ci-dessus est un extrait d’un fichier de configuration application.conf. Il contient 3 fois la même propriété nommée application.mode. Certaines sont suffixées ce qui permet de donner une valeur précise selon si l’application est lancée en intégration ou en production. Par défaut, la valeur sera celle de ligne 3 si le paramètre n’est pas indiqué. C’est super pratique et très bien pensé !
Le rechargement à chaud du code et de la conf
La propriété que j’ai montré dans l’extrait du fichier application.conf dans le paragraphe précédent, est une clé très spéciale, qui permet encore à Play! de se distinguer. Elle permet d’indiquer au framework que l’application est en mode développement ou production. La distinction est très importante pour le développeur, et pour la sécurité de l’application.
Le mode dev permet au développeur un gain de temps maximum. Lors du développement, un changement sur un fichier de code ou de configuration sera pris à chaud par le framework. Un rafraîchissement de la page du navigateur, et c’est pris en compte ! C’est tout simplement du bonheur de développer dans ces conditions.
Le mode production interdit, bien entendu, le rechargement du code à chaud, mais il permet également de précompiler les fichiers java et les fichiers de templates (qui sont les fichiers permettant l’affichage des pages web). Les performances sont donc meilleures en mode production qu’en mode développement.
Sans état !
Play! est un framework sans état. Cela signifie qu’aucune session n’est conservée du côté du serveur. Cette philosophie est à l’opposée de la plupart des frameworks java bâtis sur la norme servlet. Cela permet à Play! de se rapprocher de la philosophie initiale du protocole HTTP où chaque requête est indépendante de la précédente, donc sans état. Le framework sait qui effectue la requête grâce au cookie.
Du côté serveur, il faut donc repenser sa manière de gérer les requêtes sans état. Par exemple, si des objets doivent être stockés pour être utilisés lors des requêtes suivantes, il faudra utiliser un cache ou la base de donnée directement. D’ailleurs à propos du cache, Play! intègre un cache directement basé sur EhCache.
Le fait que Play! soit sans état permet d’avoir une architecture scalable. Cela permet aussi au framework de gérer très facilement les requêtes de type REST qui sont également des requêtes sans état.
Encore une bonne raison d’essayer Play!.
Exemple d’URL de type REST
Allez, je vous donne un exemple de REST implémenté dans Play!. L’exemple suivant permet d’effacer une personne de l’application.
L’unique page de l’application affiche une liste de personnes. La seule action possible est d’en effacer une :
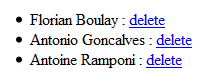
Le fait de cliquer sur le lien delete appelera une URL définie dans le fichier de configuration routes dont voici l’extrait concerné :
DELETE /person/{id} Application.deletePerson
Ce fichier définie une URL de type REST. Elle signifie qu’une URL de type /person/348 avec la méthode HTTP DELETE appelera la méthode Application.deletePerson avec le paramètre 348.
Lorsqu’on affiche la page d’accueil, la log indique :
21:00:57,315 INFO ~ URL called : GET localhost/
Ensuite, une fois que nous cliquons sur le lien delete :
21:06:24,937 INFO ~ URL called : DELETE localhost/person/2
Evidemment, l’affichage des personnes fonctionne tel qu’attendu :
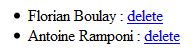
Le code java est extrêmement simple. Voici la méthode affichant l’URL et la méthode HTTP pour chaque requête HTTP :
@Before
static void printHttpInfos() {
Logger.info("URL called : %s %s", request.method, request.domain + request.path);
}
Et voici le code java permettant la suppression d’une personne :
public static void deletePerson(long id) {
Person.<Person> findById(id).delete();
index();
}
Je ne vais pas vous décrire ce que fait chaque ligne de code. Je voulais simplement montrer à quel point il est facile de faire des choses qui sont plus compliquées sans Play!. Encore une fois, n’hésitez pas à aller faire le tutoriel sur le site de Play!, on y apprend toutes les bases et notamment ce que je viens de vous montrer.
Les tests
Dans un framework moderne, la prise en charge des tests est indispensable, et Play! n’y échappe pas. Les tests Play! sont basés sur deux librairies très connues : JUnit et Selenium.
En lançant le serveur en mode test, les tests peuvent être lancés via une page dédiée sur l’application web. C’est très pratique pour lancer manuellement des tests via le browser.
D’autre part les données de tests peuvent être initialisées grâce à un fichier YAML. Voici le fichier utilisé pour initialiser les données du paragraphe précédent (dans mon cas je l’ai utilisé pour initialiser la base de données de mon application) :
Person(test1):
firstName: Florian
lastName: Boulay
Person(test2):
firstName: Antonio
lastName: Goncalves
Person(test3):
firstName: Antoine
lastName: Ramponi
Play! permet de créer 3 types de tests :
- Les tests unitaires : les classes doivent hériter de la classe UnitTest. C’est l’équivalent d’un test JUnit classique.
- Les tests fonctionnels : les classes doivent hériter de la classe FunctionnalTest. Ce sont des tests d’intégration avec l’application web.
- Les tests de validation : ce sont des tests Selenium.
Les tests fonctionnels
Je vais faire un petit zoom sur les tests dits fonctionnels.
Pour cela j’ai un peu modifié l’exemple utilisé précédemment afin d’avoir plus de cas de tests possibles. La mini application web ne comporte toujours qu’une seule page, mais elle est désormais composée de 2 listes : une liste d’employés disponibles, et une des employés d’astreinte. L’interface ressemble à ceci :

Le fait de cliquer sur on call permet de faire passer la personne d’astreinte en la mettant dans la seconde liste. Le fait de cliquer sur free permet de faire l’inverse.
Comme dit précédemment les classes de test doivent hériter de la classe FunctionnalTest. De plus, le serveur doit être lancé en mode test. Voici un exemple de test fonctionnel permettant de tester l’unique page de cette application. La première méthode teste l’état initial, c’est-à-dire les 3 personnes qui sont présentes dans la liste des employés disponibles. La seconde méthode teste le passage d’une personne de la première liste à la seconde en cliquant sur le lien on call :
public class EmployeesTest extends FunctionalTest {
@Before
public void setUp() {
Logger.debug("Reloading all data");
Fixtures.deleteAll();
Fixtures.load("data.yml");
}
@Test
public void testStartState() throws Exception {
Response response = GET("/");
// test the 200 status
assertIsOk(response);
String httpBody = getContent(response);
assertTrue(httpBody.length() > 0);
// test that 3 <li> are returned
assertContentMatch("(?s)<ul>\\s*" +
"<li>Florian Boulay.*" +
"<li>Antonio Goncalves.*" +
"<li>Antoine Ramponi.*" +
"</ul>", response);
}
@Test
public void testOnCallPeople() throws Exception {
// make Antonio Goncalves on call
Person antonio = Person.find("byFirstName", "Antonio").<Person> first();
Response response = PUT("/person/onCall/" + antonio.id, "text/html", "");
// test the 302 response
assertStatus(302, response);
String httpBody = getContent(response);
assertTrue(httpBody.length() == 0);
java.net.URL locationHeader = new java.net.URL(response.getHeader("location"));
response = GET(locationHeader.getPath());
// test the 200 response
httpBody = getContent(response);
assertTrue(httpBody.length() > 0);
assertContentMatch("(?s)<ul>\\s*" +
"<li>Florian Boulay.*" +
"<li>Antoine Ramponi.*" +
"</ul>", response);
assertContentMatch("(?s)<ul>\\s*" +
"<li>Antonio Goncalves.*" +
"</ul>", response);
}
}
Voici les quelques logs générées :
00:39:21,725 DEBUG ~ Reloading all data 00:39:21,777 INFO ~ URL called : GET localhost/ 00:39:22,469 DEBUG ~ Reloading all data 00:39:22,505 INFO ~ URL called : PUT localhost/person/onCall/8 00:39:22,525 INFO ~ URL called : GET localhost/
L’API simple
Ce qui est très agréable au quotidien avec Play! est la facilité d’utilisation des API disponibles. Je n’ai pas montré beaucoup de code dans cet article, mais vous pouvez constater la simplicité de lecture du code fait avec Play!. Cela permet comme presque tout le reste, d’avoir une marge de progression rapide, d’être opérationnel bien plus vite qu’avec d’autres framework web… Mais tout ça, je l’ai déjà dit. Je vais plutôt vous montrer quelques lignes utilisant l’API de Play!, vous pourrez vous faire une idée bien plus facilement qu’avec un long discours.
// récupérer la requête HTTP courante
Request request = Http.Request.current();
// récupérer l'EntityManager
EntityManager em = JPA.em();
// faire un appel rapide à un web service
HttpResponse response = WS.url("http://www.w3schools.com/webservices/tempconvert.asmx?op=FahrenheitToCelsius").get();
// récupérer toutes les entités Person (entité au sens objet du modèle de donnée)
List<Person> findAll = Person.findAll()
// compter le nombre d'entités Person
long count = Person.count();
// faire des requêtes simple sur l'entité Person
List<Person> allAntos = Person.find("byFirstNameLike", "anto%").fetch();
// etc......
Petit mot de la fin
Cet article touche à sa fin. J’aurais tellement voulu vous en montrer plus comme la validation super simple, les templates HTML, comment répondre au client en fonction du format qu’il demande (XML, JSON….), mais c’est déjà assez long. Je profiterai d’un prochain article pour me concentrer sur un aspect plus précis du framework.
J’espère avoir convaincu les quelques sceptiques à propos du framework Play!
Ressources
Site officiel du framework Play! : http://www.playframework.org/
Le google group très actif : http://groups.google.com/group/play-framework
Le repository git du code source de Play! : https://github.com/playframework/play
Le premier livre sur Play! : http://www.the-play-book.co.uk/